GPT-SoVITS微调训练
GPT-SoVITS微调训练
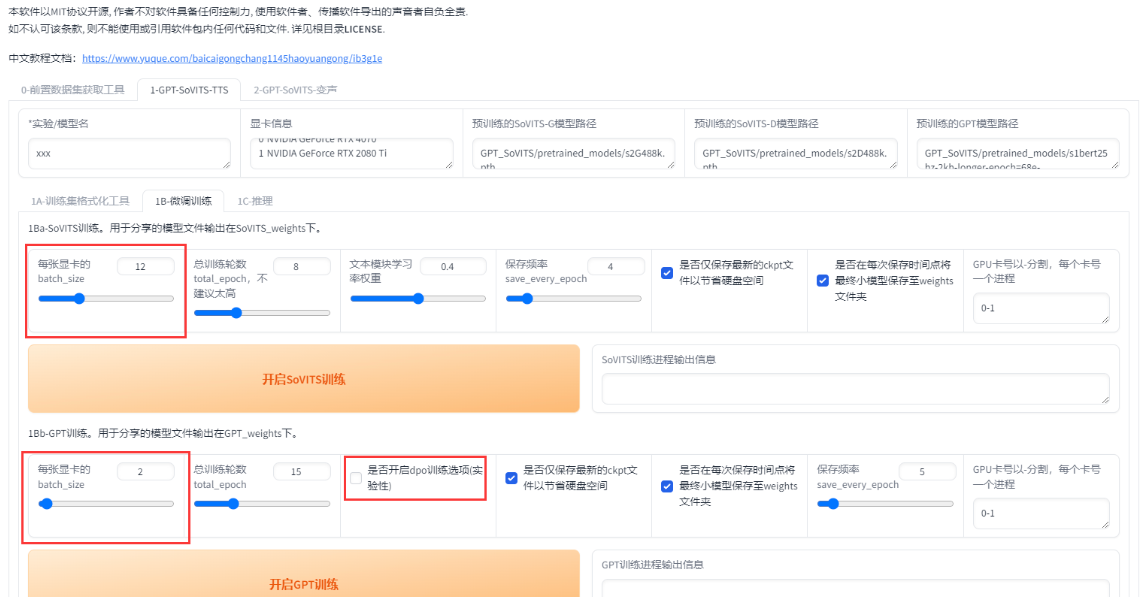
1. 设置batch_size
在进行 GPT-SoVITS 微调时,batch_size 的选择非常重要,以下是一些设置建议:
什么是 batch_size?
batch_size(批量大小)指的是在一次训练迭代中,模型所处理的训练样本数量。更简单地说,batch_size 就是一次性输入到模型中的数据量。比如,如果 batch_size 设置为 16,那么每次迭代时,模型就会从数据集中选择 16 个样本进行训练。较大的 batch_size 会让每次迭代计算更多数据,但会占用更多的显存。
设置建议:
显存限制:
batch_size不应设置过高,通常建议将其设置为显存的一半以下。如果batch_size设置过大,可能会导致显存爆满,甚至无法训练。显存过载时,训练过程会变慢,因为显卡可能会开始使用系统内存。效率与性能:
batch_size的选择并不是越大越好。虽然较大的batch_size可以在每次迭代中处理更多数据,从而提高训练效率,但也会增加显存占用,导致显卡的 3D 占用率增加,使用共享显存,从而减慢训练速度。根据数据集调整:根据数据集的大小调整
batch_size。例如,在显存为 6GB 的显卡上,推荐将batch_size设置为 1。笔者的12GB显存显卡上,将batch_size设置为 5。将如果数据集更大或者切片长度更长时,应适当减小batch_size。实际设置:在切片长度为 10 秒的情况下,以下是不同显存下的最大
batch_size:
在windows 和 linux命令行中查看显存使用情况,可以使用 nvidia-smi 命令:
1 | |
| 显存大小 | 最大 batch_size |
|---|---|
| 6GB | 1 |
| 8GB | 2 |
| 16GB | 8 |
如果切片长度更长或数据集更大,建议适当减少 batch_size。
2. 是否使用 DPO 训练
DPO(Differentiable Prompt Optimization)训练方法是 GPT-SoVITS 在0213版本之后添加的一种新方法。通过使提示(prompt)能够进行微分,DPO可以在训练过程中自动优化提示,从而显著提高模型的生成效果。它能够减少“吞字”和“复读”现象,并且使得模型可以处理更多字数的文本。然而,DPO训练也有一些挑战,特别是在显存占用和训练速度方面。
什么是“微分”?
在机器学习和神经网络中,微分(differentiation)通常是指计算损失函数(loss function)对模型参数的梯度。通过这个梯度信息,可以指导模型参数如何调整,以最小化损失函数,从而提高模型的性能。
使提示能够进行微分
传统上,提示(prompt)是固定的、手动设计的文本,不会在训练过程中进行调整。而在 DPO 方法中,提示被视为可以优化的参数,也就是说,通过训练的过程,我们可以调整这些提示的内容,使得模型的表现更加优秀。这意味着提示本身是“可微的”,也可以像神经网络的权重一样通过梯度下降来进行优化。
具体来说,使提示可微分的过程可能涉及以下几个步骤:
将提示视为可训练的参数:
在模型训练时,提示不仅是一个固定的文本,而是一个可优化的对象。我们可以用一个变量表示提示内容,并通过梯度下降法来优化这个变量。计算提示的梯度:
通过计算模型生成结果和真实目标之间的损失函数(例如,生成文本与实际文本的差异),然后对提示内容计算梯度。这个梯度表示了如何调整提示的内容,以使模型输出更加接近预期。反向传播优化提示:
通过反向传播,利用损失函数的梯度信息来更新提示内容,使其能够更好地引导模型生成高质量的文本。
举个简单的例子:
假设我们正在训练一个生成诗歌的模型,我们给定一个初始提示:”写一首关于秋天的诗”,但希望优化这个提示,以便模型生成的诗歌更加优美。传统的做法是手动修改提示,比如修改为:”写一首描述秋天景色的诗”,但是在 DPO 中,我们可以通过训练自动优化这个提示。
- 初始提示: “写一首关于秋天的诗”。
- 模型生成的诗歌: 秋天的树叶掉落,秋天的风很凉。
- 计算损失:通过计算这个生成文本与目标文本(例如:一首优美的秋天诗)之间的差异,我们可以计算损失。
- DPO优化后的提示: DPO 通过反向传播调整提示,使其变成:”写一首生动描绘秋天景色和情感的诗”。
- 新的模型输出: 新的提示引导模型生成更符合目标的诗歌。
DPO训练的优缺点:
优点:
- 效果提升:通过优化提示,DPO能够显著改善生成文本的质量,减少吞字和复读问题,提高生成文本的连贯性和准确性。
- 推理能力增强:DPO训练能够使模型处理更多的字数,在推理时生成更长的文本。
缺点:
- 显存需求增加:DPO训练需要更多的显存,通常显存占用会是传统训练方法的两倍以上,因此需要至少12GB显存的显卡。
- 训练速度变慢:DPO训练比传统方法慢约4倍,需要更长的训练时间。
- 数据集质量要求高:DPO对数据集的质量要求较高,数据集中的杂音、混响或标注错误会导致模型效果下降,甚至可能产生负面影响。
是否开启DPO训练:
开启DPO训练的条件:
- 显卡显存大于12GB。
- 训练数据集质量较好(无杂音,标注准确)。
- 能够接受较长的训练时间。
不推荐开启DPO训练的情况:
- 显卡显存小于12GB。
- 数据集质量不理想(例如,音质差或标注不准确)。
- 希望快速完成训练任务。
显存与 batch_size 配置表
| 显存 | 未开启 DPO batch_size |
开启 DPO batch_size |
切片长度 |
|---|---|---|---|
| 6GB | 1 | 无法训练 | 10s |
| 8GB | 2 | 无法训练 | 10s |
| 12GB | 4 | 1 | 10s |
| 16GB | 7 | 1 | 10s |
| 22GB | 10 | 4 | 10s |
| 24GB | 11 | 6 | 10s |
| 32GB | 16 | 6 | 10s |
| 40GB | 21 | 8 | 10s |
| 80GB | 44 | 18 | 10s |
3.设置轮数
在机器学习和神经网络中,轮数(Epoch)是指整个训练数据集通过模型一次的过程。每一轮(epoch)中,模型会使用训练数据集中的所有样本进行一次前向传播和反向传播的过程,更新模型的权重。
轮数的作用
- 训练不够:如果轮数过少,模型可能没有足够的时间去学习数据中的模式,导致欠拟合。
- 过度训练:如果轮数过多,模型可能会过度拟合训练数据,导致泛化能力下降。
选择适当的轮数:
通常在训练过程中,通过监控验证集的性能来选择适当的轮数。如果训练损失持续减少,但验证损失开始上升,可能就到了过拟合的临界点,此时应停止。
- 当底噪、混响、喷麦、响度不统一、电流声、口水音、口齿不清、音质差等情况那么请不要调高SoVITS模型轮数,否则会有负面效果。
- GPT-SoVITS模型轮数一般情况下不高于20,建议设置10。